 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Shadows: The Gaussian-Discrete Duality in Masked Diffusion
Jan 31, 2026Masked discrete diffusion is a dominant paradigm for high-quality language modeling where tokens are iteratively corrupted to a mask state, yet its inference efficiency is bottlenecked by the lack of deterministic sampling tools. While diffusion duality enables deterministic distillation for uniform models, these approaches generally underperform masked models and rely on complex integral operators. Conversely, in the masked domain, prior methods typically assume the absence of deterministic trajectories, forcing a reliance on stochastic distillation. To bridge this gap, we establish explicit Masked Diffusion Duality, proving that the masked process arises as the projection of a continuous Gaussian process via a novel maximum-value index preservation mechanism. Furthermore, we introduce Masked Consistency Distillation (MCD), a principled framework that leverages this duality to analytically construct the deterministic coupled trajectories required for consistency distillation, bypassing numerical ODE solvers. This result strictly improves upon prior stochastic distillation methods, achieving a 16$\times$ inference speedup without compromising generation quality. Our findings not only provide a solid theoretical foundation connecting masked and continuous diffusion, but also unlock the full potential of consistency distillation for high-performance discrete generation. Our code is available at https://anonymous.4open.science/r/MCD-70FD.
Almost Linear Convergence under Minimal Score Assumptions: Quantized Transition Diffusion
May 28, 2025Continuous diffusion models have demonstrated remarkable performance in data generation across various domains, yet their efficiency remains constrained by two critical limitations: (1) the local adjacency structure of the forward Markov process, which restricts long-range transitions in the data space, and (2) inherent biases introduced during the simulation of time-inhomogeneous reverse denoising processes. To address these challenges, we propose Quantized Transition Diffusion (QTD), a novel approach that integrates data quantization with discrete diffusion dynamics. Our method first transforms the continuous data distribution $p_*$ into a discrete one $q_*$ via histogram approximation and binary encoding, enabling efficient representation in a structured discrete latent space. We then design a continuous-time Markov chain (CTMC) with Hamming distance-based transitions as the forward process, which inherently supports long-range movements in the original data space. For reverse-time sampling, we introduce a \textit{truncated uniformization} technique to simulate the reverse CTMC, which can provably provide unbiased generation from $q_*$ under minimal score assumptions. Through a novel KL dynamic analysis of the reverse CTMC, we prove that QTD can generate samples with $O(d\ln^2(d/\epsilon))$ score evaluations in expectation to approximate the $d$--dimensional target distribution $p_*$ within an $\epsilon$ error tolerance. Our method not only establishes state-of-the-art inference efficiency but also advances the theoretical foundations of diffusion-based generative modeling by unifying discrete and continuous diffusion paradigms.
Multi-Step Consistency Models: Fast Generation with Theoretical Guarantees
May 02, 2025Consistency models have recently emerged as a compelling alternative to traditional SDE based diffusion models, offering a significant acceleration in generation by producing high quality samples in very few steps. Despite their empirical success, a proper theoretic justification for their speed up is still lacking. In this work, we provide the analysis which bridges this gap, showing that given a consistency model which can map the input at a given time to arbitrary timestamps along the reverse trajectory, one can achieve KL divergence of order $ O(\varepsilon^2) $ using only $ O\left(\log\left(\frac{d}{\varepsilon}\right)\right) $ iterations with constant step size, where d is the data dimension. Additionally, under minimal assumptions on the data distribution an increasingly common setting in recent diffusion model analyses we show that a similar KL convergence guarantee can be obtained, with the number of steps scaling as $ O\left(d \log\left(\frac{d}{\varepsilon}\right)\right) $. Going further, we also provide a theoretical analysis for estimation of such consistency models, concluding that accurate learning is feasible using small discretization steps, both in smooth and non smooth settings. Notably, our results for the non smooth case yield best in class convergence rates compared to existing SDE or ODE based analyses under minimal assumptions.
Capturing Conditional Dependence via Auto-regressive Diffusion Models
Apr 30, 2025Diffusion models have demonstrated appealing performance in both image and video generation. However, many works discover that they struggle to capture important, high-level relationships that are present in the real world. For example, they fail to learn physical laws from data, and even fail to understand that the objects in the world exist in a stable fashion. This is due to the fact that important conditional dependence structures are not adequately captured in the vanilla diffusion models. In this work, we initiate an in-depth study on strengthening the diffusion model to capture the conditional dependence structures in the data. In particular, we examine the efficacy of the auto-regressive (AR) diffusion models for such purpose and develop the first theoretical results on the sampling error of AR diffusion models under (possibly) the mildest data assumption. Our theoretical findings indicate that, compared with typical diffusion models, the AR variant produces samples with a reduced gap in approximating the data conditional distribution. On the other hand, the overall inference time of the AR-diffusion models is only moderately larger than that for the vanilla diffusion models, making them still practical for large scale applications. We also provide empirical results showing that when there is clear conditional dependence structure in the data, the AR diffusion models captures such structure, whereas vanilla DDPM fails to do so. On the other hand, when there is no obvious conditional dependence across patches of the data, AR diffusion does not outperform DDPM.
What Makes In-context Learning Effective for Mathematical Reasoning: A Theoretical Analysis
Dec 11, 2024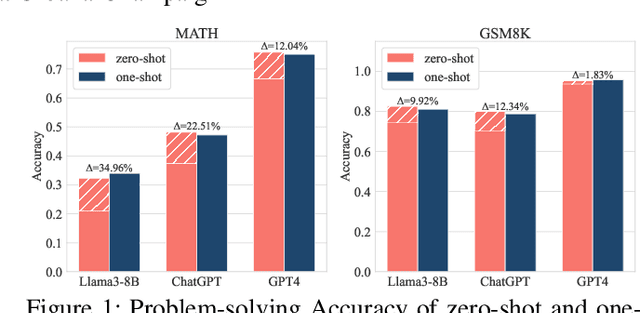



Owing to the capability of in-context learning, large language models (LLMs) have shown impressive performance across diverse mathematical reasoning benchmarks. However, we find that few-shot demonstrations can sometimes bring negative performance and their effectiveness on LLMs' reasoning abilities remains unreliable. To this end, in this paper, we aim to theoretically analyze the impact of in-context demonstrations on LLMs' reasoning performance. We prove that the reasoning efficacy (measured by empirical prediction loss) can be bounded by a LLM-oriented semantic similarity and an inference stability of demonstrations, which is general for both one-shot and few-shot scenarios. Based on this finding, we propose a straightforward, generalizable, and low-complexity demonstration selection method named LMS3. It can adaptively facilitate to select the most pertinent samples for different LLMs and includes a novel demonstration rejection mechanism to automatically filter out samples that are unsuitable for few-shot learning. Through experiments on three representative benchmarks, two LLM backbones, and multiple few-shot settings, we verify that our LMS3 has superiority and achieves consistent improvements on all datasets, which existing methods have been unable to accomplish.
Faster Sampling via Stochastic Gradient Proximal Sampler
May 27, 2024Stochastic gradients have been widely integrated into Langevin-based methods to improve their scalability and efficiency in solving large-scale sampling problems. However, the proximal sampler, which exhibits much faster convergence than Langevin-based algorithms in the deterministic setting Lee et al. (2021), has yet to be explored in its stochastic variants. In this paper, we study the Stochastic Proximal Samplers (SPS) for sampling from non-log-concave distributions. We first establish a general framework for implementing stochastic proximal samplers and establish the convergence theory accordingly. We show that the convergence to the target distribution can be guaranteed as long as the second moment of the algorithm trajectory is bounded and restricted Gaussian oracles can be well approximated. We then provide two implementable variants based on Stochastic gradient Langevin dynamics (SGLD) and Metropolis-adjusted Langevin algorithm (MALA), giving rise to SPS-SGLD and SPS-MALA. We further show that SPS-SGLD and SPS-MALA can achieve $\epsilon$-sampling error in total variation (TV) distance within $\tilde{\mathcal{O}}(d\epsilon^{-2})$ and $\tilde{\mathcal{O}}(d^{1/2}\epsilon^{-2})$ gradient complexities, which outperform the best-known result by at least an $\tilde{\mathcal{O}}(d^{1/3})$ factor. This enhancement in performance is corroborated by our empirical studies on synthetic data with various dimensions, demonstrating the efficiency of our proposed algorithm.
Reverse Transition Kernel: A Flexible Framework to Accelerate Diffusion Inference
May 26, 2024


To generate data from trained diffusion models, most inference algorithms, such as DDPM, DDIM, and other variants, rely on discretizing the reverse SDEs or their equivalent ODEs. In this paper, we view such approaches as decomposing the entire denoising diffusion process into several segments, each corresponding to a reverse transition kernel (RTK) sampling subproblem. Specifically, DDPM uses a Gaussian approximation for the RTK, resulting in low per-subproblem complexity but requiring a large number of segments (i.e., subproblems), which is conjectured to be inefficient. To address this, we develop a general RTK framework that enables a more balanced subproblem decomposition, resulting in $\tilde O(1)$ subproblems, each with strongly log-concave targets. We then propose leveraging two fast sampling algorithms, the Metropolis-Adjusted Langevin Algorithm (MALA) and Underdamped Langevin Dynamics (ULD), for solving these strongly log-concave subproblems. This gives rise to the RTK-MALA and RTK-ULD algorithms for diffusion inference. In theory, we further develop the convergence guarantees for RTK-MALA and RTK-ULD in total variation (TV) distance: RTK-ULD can achieve $\epsilon$ target error within $\tilde{\mathcal O}(d^{1/2}\epsilon^{-1})$ under mild conditions, and RTK-MALA enjoys a $\mathcal{O}(d^{2}\log(d/\epsilon))$ convergence rate under slightly stricter conditions. These theoretical results surpass the state-of-the-art convergence rates for diffusion inference and are well supported by numerical experiments.
An Improved Analysis of Langevin Algorithms with Prior Diffusion for Non-Log-Concave Sampling
Mar 10, 2024Understanding the dimension dependency of computational complexity in high-dimensional sampling problem is a fundamental problem, both from a practical and theoretical perspective. Compared with samplers with unbiased stationary distribution, e.g., Metropolis-adjusted Langevin algorithm (MALA), biased samplers, e.g., Underdamped Langevin Dynamics (ULD), perform better in low-accuracy cases just because a lower dimension dependency in their complexities. Along this line, Freund et al. (2022) suggest that the modified Langevin algorithm with prior diffusion is able to converge dimension independently for strongly log-concave target distributions. Nonetheless, it remains open whether such property establishes for more general cases. In this paper, we investigate the prior diffusion technique for the target distributions satisfying log-Sobolev inequality (LSI), which covers a much broader class of distributions compared to the strongly log-concave ones. In particular, we prove that the modified Langevin algorithm can also obtain the dimension-independent convergence of KL divergence with different step size schedules. The core of our proof technique is a novel construction of an interpolating SDE, which significantly helps to conduct a more accurate characterization of the discrete updates of the overdamped Langevin dynamics. Our theoretical analysis demonstrates the benefits of prior diffusion for a broader class of target distributions and provides new insights into developing faster sampling algorithms.
Faster Sampling without Isoperimetry via Diffusion-based Monte Carlo
Jan 12, 2024



To sample from a general target distribution $p_*\propto e^{-f_*}$ beyond the isoperimetric condition, Huang et al. (2023) proposed to perform sampling through reverse diffusion, giving rise to Diffusion-based Monte Carlo (DMC). Specifically, DMC follows the reverse SDE of a diffusion process that transforms the target distribution to the standard Gaussian, utilizing a non-parametric score estimation. However, the original DMC algorithm encountered high gradient complexity, resulting in an exponential dependency on the error tolerance $\epsilon$ of the obtained samples. In this paper, we demonstrate that the high complexity of DMC originates from its redundant design of score estimation, and proposed a more efficient algorithm, called RS-DMC, based on a novel recursive score estimation method. In particular, we first divide the entire diffusion process into multiple segments and then formulate the score estimation step (at any time step) as a series of interconnected mean estimation and sampling subproblems accordingly, which are correlated in a recursive manner. Importantly, we show that with a proper design of the segment decomposition, all sampling subproblems will only need to tackle a strongly log-concave distribution, which can be very efficient to solve using the Langevin-based samplers with a provably rapid convergence rate. As a result, we prove that the gradient complexity of RS-DMC only has a quasi-polynomial dependency on $\epsilon$, which significantly improves exponential gradient complexity in Huang et al. (2023). Furthermore, under commonly used dissipative conditions, our algorithm is provably much faster than the popular Langevin-based algorithms. Our algorithm design and theoretical framework illuminate a novel direction for addressing sampling problems, which could be of broader applicability in the community.
Monte Carlo Sampling without Isoperimetry: A Reverse Diffusion Approach
Jul 05, 2023



The efficacy of modern generative models is commonly contingent upon the precision of score estimation along the diffusion path, with a focus on diffusion models and their ability to generate high-quality data samples. This study delves into the potentialities of posterior sampling through reverse diffusion. An examination of the sampling literature reveals that score estimation can be transformed into a mean estimation problem via the decomposition of the transition kernel. By estimating the mean of the auxiliary distribution, the reverse diffusion process can give rise to a novel posterior sampling algorithm, which diverges from traditional gradient-based Markov Chain Monte Carlo (MCMC) methods. We provide the convergence analysis in total variation distance and demonstrate that the isoperimetric dependency of the proposed algorithm is comparatively lower than that observed in conventional MCMC techniques, which justifies the superior performance for high dimensional sampling with error tolerance. Our analytical framework offers fresh perspectives on the complexity of score estimation at various time points, as denoted by the properties of the auxiliary distribution.